
Kom, we doen een experiment. We laten één schoolklas elke dag meerdere liters energydrinks bij elke maaltijd drinken, en een tweede klas niet. Eens we vaststellen dat de leerlingen van de ene klas tot ‘s avonds laat hyperactief rondrennen in plaats van in slaap te vallen, is dat dan toeval of niet? Het meest voor de hand liggende antwoord is: waarschijnlijk niet.
We gaan ervan uit dat die monsterhoeveelheid stimulerende dranken de oorzaak is van de slapeloosheid van de kinderen. Maar hoe zeker kunnen we daarvan zijn? Om onze veronderstellingen met statistiek te kunnen te bevestigen, moeten we de mogelijkheid van een toeval als een variabele aan de vergelijking toevoegen.
Videos by VICE
Dat doen wetenschappers met de zogenaamde p-waarde. Sinds de jaren twintig gebruiken de meeste wetenschappers daarvoor een waarde van p=0,05 of 5%, om in te schatten hoe waarschijnlijk het is dat het resultaat van de meting puur toevallig was. In ons voorbeeld: dat er in de steekproef gewoon bijzonder veel hyperactieve kinderen waren – en hun gedrag niets te maken heeft met de energydrinks die ze dronken. Als we de berekening met de p-waarde maken, krijgen we uiteindelijk een waarde tussen 0 en 1. Als ons resultaat heel dicht bij 0 ligt, kunnen we de champagneflessen alvast openmaken. Ons resultaat geldt dan in de wetenschap als “statistisch significant”, wat ons een artikel in een prestigieus vakblad, en dus onderzoeksroem en eer, kan opleveren.
De p-waarde wordt gezien als een onbetwistbare standaard om data aan een statistisch model te toetsen, maar dat is het in feite niet. Het maakt niet waar wat het beweert. Want eigenlijk moet de juiste p-waarde zorgvuldig bepaald worden voor elk onderzoek. Een algemene waarde is willekeurig, en helemaal niet zo veelzeggend en objectief als het lijkt.
Dat we de vaste p-waarde van 5% toch nog steeds gebruiken, is eigenlijk een paradox. Hij veroorzaakt namelijk zo vaak niet reproduceerbare onderzoeksresultaten, dat de grootste statistiekpublicatie ter wereld besloot een groot pamflet over het probleem met de p-waarde te publiceren. “Voor alle duidelijkheid”, klinkt het daar een beetje betweterig, “statistici slaan al meedere decennia lang alarm hierover”.
In 1925 had de beroemde statisticus Ronald Fisher het behoorlijk willekeurige idee om de p-waarde bij statistische testen op vijf procent vast te leggen, om zo false positives en foutnegatieven false negatives te vermijden (Zie afbeelding hieronder). Sindsdien is er weinig veranderd. Fisher inspireerde zich toen trouwens op de tabel van een Guinness-bierbrouwer. Die vijf procent-waarde of overschrijdingskans staat ondertussen in elk statistiekboek. Dat dat nog steeds zo is, noemen sommigen het “vuile geheim van de wetenschap”.

Nog steeds leren geeuwende studenten dat de kans op een toevalstreffer 5% bedraagt. Gediplomeerde wetenschappers bewerken hun data op hun beurt zo lang tot hun resultaten als “statistisch significant” te boek staan. Die praktijk staat ook bekend als p-Hacking.
Maar waarom eigenlijk? Al sinds decennia discussieren weterschappers over hoe willekeurig die 5%-waarde is. Veel statistiekbeginners lijkt de vaste waarde te simpel – terecht. Ook hoogleraars geven toe dat onze statistische gereedschapskist dringend een update nodig heeft.
De discussie explodeerde pas echt in 2016, toen vakblad Nature 1500 onderzoekers vroeg de gepubliceerde onderzoeken van hun collega’s te herhalen. Het resultaat was een catastrofe: 70 procent van de bevraagden lieten weten dat ze er niet in waren geslaagd om de experimenten van hun voorgangers te reproduceren: ze behaalden niet dezelfde significante resultaten. Dat heeft de wetenschap in een “crisis van de reproduceerbaarheid” gestort. En dat is een gigantisch probleem: de reproduceerbaarheid is een essentiële zuil van het wetenschappelijke werk.
Zie het zo: iemand leest een studie die een wetenschapper heeft geschreven. Als hij die studie wil herhalen, en hij heeft heeft hetzelfde gereedschap tot zijn beschikking, dan zou hij dezelfde resultaten moeten krijgen. Anders hadden de wetenschappers in kwestie ook meteen iets uit hun duim kunnen zuigen.
Geneeskunde, economie, psychologie en scheikunde verkeren in een zware crisis vandaag de dag – en dat heeft niet noodzakelijk iets te maken met de anti-wetenschappelijke Donald Trump. Het gaat hier om de essentie: ons vertrouwen in de onderzoekswetenschappen.
61 van de 100 psychologiestudies zijn niet repliceerbaar, blijkt uit een ander groot experiment. De conclusies van die studies zijn daardoor zo goed als waardeloos geworden. Ook in andere disciplines, zoals economie of chemie, brengen meta-onderzoeken desastreuze resultaten met zich mee. En een bekende studie bij de geneeskundige publicatie PLOS One draagt simpelweg de titel : “Waarom de meeste gepubliceerde onderzoeksresultaten fout zijn”.
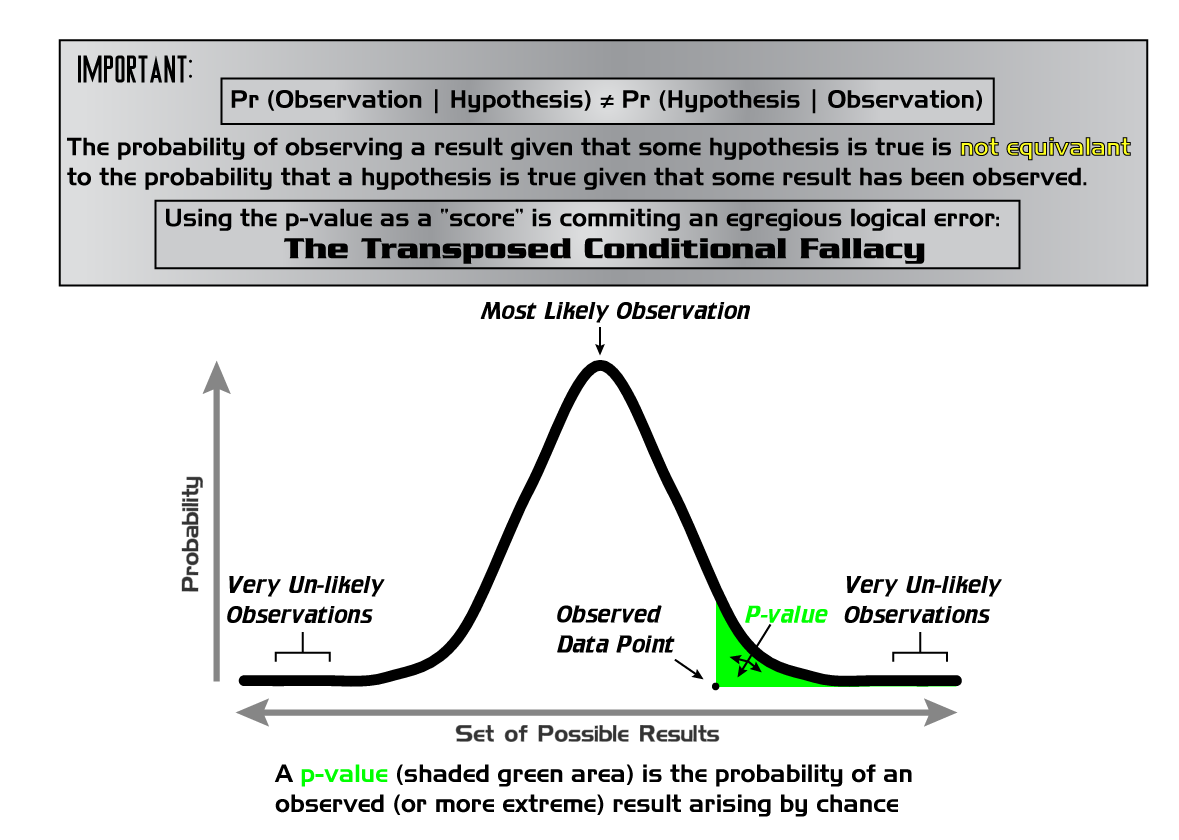
In veel disciplines wordt de p-waarde nog steeds als een soort waarheidsscore gebruikt. Nieuwe, significante resultaten worden door hun nieuwswaarde namelijk vaker in wetenschappelijke bladen gepubliceerd dan herhalingsonderzoeken van eerdere studies. Daaraan is niets veranderd in een tijd waarin later vaak blijkt dat die nieuwe onderzoeken helemaal niet repliceerbaar zijn, en hun resultaten massaal foutposifieven opleveren: een effect vaststellen dat eigenlijk niet meer is dan een “fout alarm”. Daarbovenop is de druk om publiceerbare resultaten te produceren hoog, vooral bij jonge onderzoekers.
Ondertussen komt er beweging in de onderzoeksgemeenschap: 72 onderzoekers uit verschillende disciplines hebben samen een vakoverschrijdende paper geschreven. Hun voorstel is even simpel als efficiënt: verklein de grens van significantie, of drempelwaarde, van 0.05 naar 0.005. Alle resultaten die tussen die twee waarden liggen, zijn dan slechts “suggestief”: het staat nog niet vast of er werkelijk sprake is van een meetbaar effect.
In twee wetenschappelijke disciplines is deze drempelwaarde al verkleind: de genetica en de deeltjesfysica. Dat legde ze geen windeieren: de genetica staat bekend als discipline met stabiele resultaten. Ook in haar geval kwam de aanzet tot verandering van geneticawetenschappers die zich zorgen maakten over de betrouwbaarheid van hun resultaten.
De vele onderzoekers uit disciplines met onlangs in opspraak geraakte resultaten, die nu een striktere drempelwaarde eisen, bewijzen de grote steun voor dit idee.
Het is nu afwachten tot ook de redacteurs van belangrijke wetenschappelijke vakbladen die nieuwe drempelwaarde aanvaarden. In dat geval zouden hun pagina’s behoorlijk leeg blijven: er zijn maar heel weinig onderzoeken die volgens de strengere drempelwaarde nog statistisch significant zijn. Anderzijds zou het een impuls geven voor meer herhalingsonderzoeken (of “replicatiestudies”) van vroegere studies. Dat is voor de meeste onderzoekers echter niet sexy genoeg. Een studie herhalen, en zo de bestaande resultaten sterker bevestigen, is nu eenmaal niet zo opwindend als een volledig nieuw, baanbrekend onderzoek.
De p-waarde verkleinen kent nog een probleem: om dezelfde statistische relevantie te hebben, zou de steekproefgrootte – zoals het aantal scholieren in onze energydrinkstudie – bijna 70 procent groter moeten zijn. We hebben dus meer leerlingen, meer Red Bull en meer geld nodig. Wetenschappelijk betrouwbare inzichten, die de test van de tijd kunnen doorstaan en ook voor de onderzoekers van morgen nog van nut zijn, komen dus tegen een prijs.



